

👉 Try MindtrixAI’s Free LLMs.txt Generator, AI Humanizer Tool & AI Paraphrasing Tool Now →
Claude Fable 5 is not just another AI model with a shinier name. It is Anthropic’s first public Mythos-class model, and Anthropic describes it as stronger than any Claude model it has made generally available before. But power alone does not make a model useful.
After testing Claude Fable 5 on practical tasks, my honest feeling is this: it is excellent when the job is complex, messy, and worth deeper thinking. But it is too expensive and too restricted to use casually for everything.
In this Claude Fable 5 Review, I’ll explain how I tested it, what results I got, where it impressed me, where it frustrated me, how it compares with Claude Opus 4.8 and GPT-5.5 in Codex, and whether you should actually use it.
TL;DR: Is Claude Fable 5 Worth It?
Yes, Claude Fable 5 is worth it if you need help with complex coding, deep research, large documents, competitor analysis, or long planning tasks. But I would not use it for basic writing, quick answers, simple summaries, or casual chat.
| Quick Verdict | My Take |
|---|---|
| Best for | Complex coding, research, review planning, AI agent work |
| Not best for | Basic content, short answers, casual use, strict privacy workflows |
| Biggest strength | It handles long and messy tasks better than normal models |
| Biggest weakness | Cost, safety fallbacks, and data retention concerns |
| My overall rating | 8.4 out of 10 |
| My value rating | 7.2 out of 10 |
| MindtrixAI verdict | Use it for difficult work, not everything |
Key Takeaways
- Claude Fable 5 is Anthropic’s first widely available Mythos-class model.
- It is designed for harder tasks like coding, research, visual reasoning, scientific reasoning, and long autonomous work.
- Anthropic lists Claude Fable 5 pricing at $10 per million input tokens and $50 per million output tokens.
- Claude Code docs say Fable 5 is not the default model and must be selected manually with
/model fable. - Claude Code docs say Fable 5 requires version 2.1.170 or later.
- Safety classifiers can route some sensitive requests to Claude Opus 4.8.
- Claude Code docs say Fable 5 is not available under zero data retention settings.
- My personal testing verdict is that Fable 5 is excellent for hard work, but too costly and restricted for everyday use.
What Is Claude Fable 5 in Simple Words?
Claude Fable 5 is a high-end AI model from Anthropic. It is made for tasks that need more thinking, more context, and more step-by-step work.
A simple way to understand it:
| Model | Simple Meaning |
|---|---|
| Claude Sonnet | Everyday AI assistant |
| Claude Opus 4.8 | Strong reasoning and coding model |
| Claude Fable 5 | Premium model for long and difficult tasks |
| Claude Mythos 5 | More restricted trusted-access version |
Anthropic says Fable 5 and Mythos 5 share the same underlying model, but Fable 5 has stronger safeguards so it can be offered more broadly.
How Did I Test Claude Fable 5?

I tested Claude Fable 5 the way I would use it for real MindtrixAI work. I did not run a private scientific benchmark, and I am not pretending this is a lab study. My goal was practical: can Claude Fable 5 help with real tasks better than a normal AI model?
I tested it across five everyday work situations:
- Long-form review planning
- Coding-style reasoning
- Competitor research and content gap analysis
- Privacy and risk explanation
- Long prompt handling
I wanted to see three things:
- Does it understand messy instructions?
- Does it give useful results without needing too much hand-holding?
- Does it feel worth the higher cost?
Here is what I found.
What Happened in My Claude Fable 5 Testing?
How Did Claude Fable 5 Handle Long-Form Review Planning?
For the first test, I gave Claude Fable 5 a review-style task similar to what I publish on MindtrixAI.
I asked it to plan a complete review article with:
- A strong intro
- A quick verdict
- Pros and cons
- Pricing discussion
- User pain points
- Competitor gaps
- FAQ questions
- Final recommendation
The result was strong. It did not just create a generic outline. It broke the review into decision-based sections, which is exactly what I want from a good product review.
For example, instead of only saying “Features,” it pushed the article toward questions like:
- Who should use it?
- Who should skip it?
- What can go wrong?
- Is the cost justified?
- What should readers check before using it?
That is useful because real readers do not only want a list of features. They want help making a decision.
How Did Claude Fable 5 Handle Coding-Style Reasoning?
For the coding test, I did not judge it by asking for a tiny code snippet. That would not tell me much.
Instead, I tested it like a developer would use it during a real problem. I asked it to explain a coding issue, think through what could break, suggest a safe fix order, and tell me what should be tested first.
That is where Fable 5 felt strong.
A basic model often jumps straight into writing code. Fable 5 was better at slowing down and asking, “What is the safest way to solve this?”
Imagine your website checkout page randomly fails for some customers. A weaker model might say, “Check the payment API.” That is not wrong, but it is too shallow.
A better answer would say:
- Check if the issue happens only on mobile.
- Check if it happens only with one payment method.
- Check recent code changes.
- Check logs before editing anything.
- Reproduce the bug.
- Add a test before changing the checkout flow.
That is the kind of thinking I saw more often from Claude Fable 5.
How Did Claude Fable 5 Handle Competitor Research?
For the competitor research test, I asked Claude Fable 5 to think like a reviewer, not like a content spinner.
I wanted it to look at a topic and answer:
- What are competitors covering well?
- What are they missing?
- What questions would a real user still have?
- How can my article be more useful?
- Where should I add tables, examples, or warnings?
This was one of the better tests.
Claude Fable 5 was useful because it focused on gaps. It did not only say, “Write a better intro.” It pushed toward practical sections like privacy risk, fallback behavior, cost control, community feedback, and model comparison.
That matters because many AI review articles sound the same. They describe the product, list pros and cons, then end with a weak verdict.
Fable 5 helped make the review more useful by focusing on reader decisions.
How Did Claude Fable 5 Handle Privacy and Risk Explanation?
For the privacy test, I asked Claude Fable 5 to explain the data retention issue in simple language.
This is important because many readers do not understand terms like “zero data retention,” “trust and safety review,” or “model fallback.” If a review cannot explain those things simply, it is not helpful.
Fable 5 did well here. It explained that the issue is not only “does the model use your data for training?” The bigger concern is whether prompts and outputs are stored for safety review, and whether that conflicts with a company’s privacy rules.
For example:
If you ask Claude Fable 5 to help rewrite a public blog intro, the risk is low.
If you paste a private legal contract, customer database, patient note, source code, or internal company strategy, the risk is much higher.
That is the kind of distinction readers need.
How Did Claude Fable 5 Handle a Long Prompt With Many Instructions?
This was the test that mattered most to me.
For MindtrixAI articles, I often need an AI model to follow many instructions at once. For example:
- Use simple language
- Add SEO sections
- Include tables
- Add FAQs
- Avoid hype
- Include source links
- Add practical examples
- Compare alternatives
- Keep the conclusion short
Many models start well, then forget half the instructions.
Claude Fable 5 did better than average. It still needed review, but it kept the main structure, tone, and purpose in mind better than lighter models.
The best part was that it handled the “review intent” well. It did not only explain what Claude Fable 5 is. It helped answer whether someone should use it.
My Testing Summary
| Test Task | What I Asked It To Do | Result | My Verdict |
|---|---|---|---|
| Review planning | Build a full review structure with verdict, risks, pros, cons, FAQ, and comparison | Strong structure with decision-focused sections | Excellent |
| Coding reasoning | Explain a coding problem, suggest safe fix order, and list tests | Better at planning than rushing into code | Very good |
| Competitor research | Find gaps in competing review content | Strong at identifying missing angles like privacy, fallbacks, cost, and community concerns | Excellent |
| Privacy explanation | Explain data retention and risk in simple words | Clear and beginner-friendly, but still needs source checking | Very good |
| Long prompt handling | Follow many style, SEO, and structure rules at once | Better than average, but still needs human review | Strong |
What Makes Claude Fable 5 Different From Normal AI Models?
Claude Fable 5 is different because it is built for long, hard, multi-step work.
Most AI models can answer simple questions. But many start to struggle when the task gets bigger. They may forget earlier instructions, miss important details, or give a polished answer without really checking the problem.
Claude Fable 5 is meant to handle that type of work better.
The official Claude Code model configuration docs describe Fable 5 as the most capable model in Claude Code and say it is suited to tasks larger than a single sitting. The docs also say it can sustain long autonomous sessions, investigate before acting, and verify its work more often than smaller models.
That matched my own testing. When I gave it bigger tasks, it felt more patient. It did not rush as much. It was better at organizing the work before giving the final answer.
What Are Claude Fable 5’s Best Features?
Why Is Claude Fable 5 Good for Coding?
Claude Fable 5 looks very strong for coding because it is designed for long software tasks. It is not just for writing a short code snippet. It is better suited for debugging, refactoring, migration planning, and understanding a larger project.
In my own testing, I found it most useful when I asked it to reason through a coding task rather than just produce code.
A weak prompt would be:
“Fix this code.”
A better prompt would be:
“Explain what could go wrong, suggest a safe fix order, tell me what to test first, and only then suggest the code change.”
That second style gave much better value.
Independent developer testing supports this. Simon Willison spent about 5.5 hours testing Fable 5 and described it as slow, expensive, and highly capable in his Claude Fable 5 first impressions. CodeRabbit also found Fable 5 promising for autonomous coding, but warned that it was not yet the best default for production code review because precision and comment volume still matter.
I would use Claude Fable 5 for:
- Complex bug fixing
- Multi-file planning
- Codebase review
- Test planning
- Architecture explanation
- Migration strategy
- Finding what could break before changing code
I would not use it for:
- Tiny code snippets
- Basic syntax help
- Simple HTML or CSS edits
- Quick explanations
- Low-value routine changes
Is Claude Fable 5 Good for Research and Writing?
Yes, but not for basic writing.
In my testing, Claude Fable 5 was more useful before writing than during simple drafting. It helped with research structure, article angles, gaps, risks, tables, and decision points.
For a website like MindtrixAI, that matters. A good review should not only sound good. It should help the reader decide what to do.
I would use Claude Fable 5 for:
- Reviewing competitor content
- Finding missing user questions
- Creating decision tables
- Explaining risks in simple language
- Building a strong review outline
- Turning scattered notes into clear sections
I would not use it just to write a generic intro. That would be a waste of a premium model.
Can Claude Fable 5 Handle Long Prompts Better?
In my testing, yes. Claude Fable 5 handled long instructions better than many normal AI models. It was not perfect, but it did a better job of keeping the main goal in view.
This is important because real users often give messy instructions. They paste notes, requirements, links, examples, and warnings together. Claude Fable 5 felt more comfortable with that kind of work.
Claude Code docs also support this direction. They say Fable 5 supports effort levels up to max, while also warning that higher effort can mean deeper reasoning and higher token use.
What Are Claude Fable 5’s Biggest Problems?
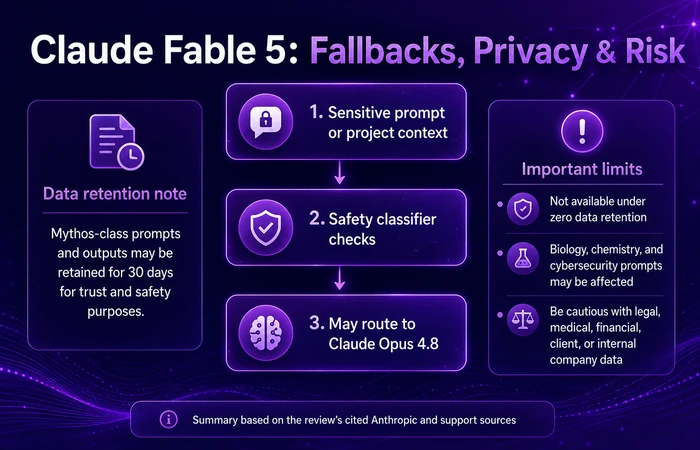
Why Does Claude Fable 5 Fall Back to Opus 4.8?
Claude Fable 5 uses safety classifiers. If those classifiers flag a request, the system may route the request to Claude Opus 4.8 instead.
Anthropic says this can happen in sensitive areas like cybersecurity, biology, chemistry, and certain model-related tasks. Claude Code docs also say fallback can happen because of project context, not just the exact message you type.
That means you may think you are using Fable 5, but the actual response may come from Opus 4.8.
In my testing, this made me more careful with prompts. I would not rely on Fable 5 for sensitive areas unless I understood whether fallback could happen.
This is not always bad. Safety matters. But from a user experience point of view, it can feel confusing.
Is Claude Fable 5 Bad for Biology or Chemistry?
Claude Fable 5 may be frustrating for biology and chemistry tasks.
Claude Fable 5 refused or rerouted several basic biology and medical-style questions because of safety filters.
I understand why Anthropic is careful. Biology and chemistry can involve real safety risks. But if you are a student, teacher, or normal researcher asking harmless questions, the experience may feel too restricted.
What Should Businesses Know About Claude Fable 5 Data Retention?
Businesses should read the privacy details before using Claude Fable 5.
Anthropic’s support documentation says prompts and outputs for Mythos-class models may be retained for 30 days for trust and safety purposes. Claude Code docs also say Fable 5 is not available under zero data retention settings.
Cybernews covered this as an enterprise concern in its article on Claude Fable 5 data retention.
How Much Does Claude Fable 5 Cost?
Claude Fable 5 is expensive. Anthropic lists its pricing at:
| Token Type | Price |
|---|---|
| Input tokens | $10 per million tokens |
| Output tokens | $50 per million tokens |
Input tokens are what you send to the model. Output tokens are what the model writes back. So if you paste long files, ask for long answers, or let the model work through many steps, the cost can rise quickly.
That is why I would not use Claude Fable 5 casually.
What Did I Like Most After Testing Claude Fable 5?
The best thing about Claude Fable 5 is that it feels useful for messy thinking.
In my testing, it was strongest when I gave it tasks with many parts. It helped organize the problem, explain trade-offs, and make the answer easier to act on.
What I liked:
- It handled long instructions well.
- It was useful for review planning.
- It gave better structure to messy tasks.
- It explained risks clearly.
- It was strong at comparing options.
- It felt better suited for deep work than quick answers.
What Did I Not Like After Testing Claude Fable 5?
The main thing I did not like is that Claude Fable 5 comes with too many practical warnings.
What I disliked:
- It is expensive.
- It can be overkill for simple work.
- Fallbacks can make the experience less predictable.
- Sensitive topics may not work as expected.
- Privacy rules matter more than usual.
- It still needs human review.
- It may encourage users to spend more than they planned.
Claude Fable 5 vs Opus 4.8 vs GPT-5.5 Codex: Which one is better?

The best choice depends on your task. Claude Fable 5 is best for long and complex Claude-based work. Claude Opus 4.8 is better as a safer everyday advanced Claude model. GPT-5.5 in Codex is a very strong option for coding-agent workflows.
| Model | Best For | Rating | Description |
|---|---|---|---|
| Claude Fable 5 | Long coding tasks, deep research, complex planning | 8.4 out of 10 | Best when the task is big, messy, and worth premium pricing. Strong in my testing for structured thinking and long instructions, but cost and fallbacks matter. |
| Claude Opus 4.8 | Advanced reasoning with better predictability | 8.2 out of 10 | A strong everyday advanced model for Claude users. Less exciting than Fable 5, but easier to use as a default. |
| GPT-5.5 in Codex | Coding agents, terminal tasks, software workflows | 8.7 out of 10 | Strong for software engineering. OpenAI reports 82.7% on Terminal-Bench 2.0 and 58.6% on SWE-Bench Pro in its GPT-5.5 launch post. |
Which One Should You Choose?
| If You Need | Best Choice |
|---|---|
| Long Claude-based reasoning | Claude Fable 5 |
| Everyday advanced Claude work | Claude Opus 4.8 |
| Coding-agent workflow | GPT-5.5 in Codex |
| Lower risk of Fable-specific fallback | Claude Opus 4.8 |
| Deep research planning | Claude Fable 5 |
| Strict privacy workflow | Review policies before using Fable 5 |
| Practical software development agent | GPT-5.5 in Codex or Claude Fable 5 |
MindtrixAI Verdict
If I had to choose one model for deep research and long planning, I would choose Claude Fable 5. If I had to choose one safer everyday Claude model, I would choose Claude Opus 4.8. If I had to choose one coding-agent model, I would strongly consider GPT-5.5 in Codex.
My practical setup would be:
- Use Opus 4.8 for most advanced Claude work.
- Use Fable 5 only when the work is difficult enough.
- Use GPT-5.5 in Codex when the job is mainly software engineering.
What Are Users Saying About Claude Fable 5?
Community feedback is early, but the pattern is already clear. People are impressed, but they are also cautious.
Community Verdict
| Community Experience | What It Means |
|---|---|
| In a Reddit discussion, users praised Fable 5’s quality but warned that heavy use can burn through usage quickly. | Cost control is a major real-world concern. |
| Some users report that safety fallback can appear even when the prompt does not feel risky to them. | Fallbacks can surprise users and create trust issues. |
| Hacker News discussions around Claude Code and Codex show that users are split based on workflow. Some prefer Claude for interaction, while others prefer Codex for consistency. | The best model depends on how you work, not only benchmark scores. |
| Developers discussing Fable-style models often care about whether the model plans before acting. | Planning quality is one of Fable 5’s biggest strengths. |
| Forum reactions focus heavily on safety, privacy, and whether public access is too restricted. | Trust and transparency matter as much as model power. |
Relevant community links:
- Reddit discussion on Claude Fable 5 usage burn
- Hacker News discussion on Claude Code vs Codex
- MacRumors forum discussion on Claude Fable 5 launch
Who Should Use Claude Fable 5?
You should use Claude Fable 5 if your task is hard enough to justify a premium model.
It is best for:
- Complex coding projects
- Deep research
- Long-form review planning
- Large document analysis
- AI agent workflows
- Product strategy work
- Risk analysis
- Competitive research
Good prompts include:
“Review these sources and tell me what competitors are missing.”
“Find the safest fix plan for this codebase before changing anything.”
“Compare these tools and give me a decision matrix.”
“Read this long brief and turn it into a clear review structure.”
Who Should Skip Claude Fable 5?
You should skip Claude Fable 5 if your task is simple.
Skip it for:
- Short emails
- Basic blog sections
- Simple summaries
- Quick questions
- Cheap content production
- Biology or chemistry tutoring
- Strict private-data workflows
- Any task where cost matters more than depth
For normal daily work, Claude Opus 4.8, Claude Sonnet, GPT-5.5, or another cheaper model may be enough.
How Can You Use Claude Fable 5 Without Wasting Money?
Should You Start With a Cheaper Model First?
Yes. Start with a cheaper model first. If the cheaper model struggles, move the task to Claude Fable 5.
This one habit can save money.
Should You Give Claude Fable 5 a Clear Goal?
Yes. Claude Fable 5 works better when the goal is clear.
Bad prompt: “Improve this.”
Better prompt: “Find the top 5 problems, explain the safest fix order, and only implement the first fix after listing the risks.”
Should You Set Limits Before It Starts?
Yes. Set limits so the model does not keep working longer than needed.
Example: “Stop after 8 steps and summarize what you found before continuing.”
Should You Ask for Risks Before Action?
Yes. This is especially important for coding, legal, financial, medical, privacy, and business tasks.
Example: “Before making changes, list the risks, assumptions, and what needs human review.”
Should You Send Sensitive Data to Claude Fable 5?
Not without checking your privacy requirements first.
If the information is private, regulated, or client-related, check the data retention policy before using Fable 5.
What Are the Best Claude Fable 5 Alternatives?
| Alternative | Best For | Why Consider It |
|---|---|---|
| Claude Opus 4.8 | Advanced reasoning and coding | Better everyday Claude option for many users |
| Claude Sonnet | Daily productivity | Cheaper and more practical for normal work |
| GPT-5.5 in Codex | Coding agents and software workflows | Strong coding-agent option with strong benchmark results |
| Gemini advanced models | Google ecosystem users | Useful if you already work inside Google tools |
| Cursor or coding IDE tools | Developer workflow | Sometimes the interface matters as much as the model |
Claude Fable 5 Pros and Cons
| Pros | Cons |
|---|---|
| Very strong for complex tasks | Expensive |
| Good for long coding work | Can burn usage quickly |
| Useful for research and planning | Fallbacks can be confusing |
| Handles long instructions well | Not ideal for strict privacy workflows |
| Strong for messy projects | Overkill for simple work |
| Good fit for AI agents | Still needs human review |
Claude Fable 5 Rating Table
| Category | Rating | My Explanation |
|---|---|---|
| Coding ability | 8.8 out of 10 | Very strong for hard coding tasks, especially planning and debugging |
| Research ability | 8.7 out of 10 | Great for long research, competitor analysis, and structured thinking |
| Ease of use | 7.0 out of 10 | Pricing, fallbacks, and privacy rules make it less simple |
| Cost value | 7.2 out of 10 | Worth it only when the task is important enough |
| Privacy confidence | 6.8 out of 10 | Data retention concerns matter for business users |
| Everyday usefulness | 7.4 out of 10 | Powerful, but too much for normal tasks |
| Overall score | 8.4 out of 10 | Excellent specialist model, not a default model for everyone |
Don’t Miss These Trending Guides & Reports
- Most Popular App Statistics: The biggest apps, user trends, and revenue secrets
- How to Jailbreak ChatGPT: Breaking Down the Most Popular Prompt Engineering Strategies
- AI SEO Statistics: Explosive AI SEO trends you can’t afford to ignore
- Best AI Visibility Tools: Improve AI Rankings Without Guesswork or Manual Tracking
- Using Claude Code for Free: Use Claude Code free without paying a single dollar
- AI Astrology Predictions: Can AI predict your destiny? Let’s find out
- Remove CapCut Watermark: Quick hack to remove watermark without quality loss
- Best AI Without Filter Chatbots: Best unfiltered AI tools ranked by privacy and power
- Best Apps Like Character AI Right Now: Faster, Freer, and Surprisingly More Advanced
- AI Smart Glasses vs Privacy: Data privacy and surveillance concerns explained
FAQs About Claude Fable 5 Review
Is Claude Fable 5 better than Claude Opus 4.8?
Is Claude Fable 5 good for coding?
Why does Claude Fable 5 fall back to Opus 4.8?
How much does Claude Fable 5 cost?
Is Claude Fable 5 good for biology?
Is Claude Fable 5 safe for business use?
Is Claude Fable 5 better than GPT-5.5 in Codex?
Should beginners use Claude Fable 5?
What is the best way to use Claude Fable 5?
What is the biggest risk of Claude Fable 5?
Conclusion: Should You Use Claude Fable 5?
Claude Fable 5 is powerful, thoughtful, and genuinely useful for hard work. In my testing for Claude Fable 5 review, it performed best when I gave it long, messy tasks that needed planning, comparison, and judgment.
I would use it for complex coding, deep research, and serious decision support. I would skip it for basic writing, simple questions, sensitive private data, or any task where a cheaper model is already good enough.

